
 Overview
Overview
Historically, ontologies arose from the branch of philosophy known as metaphysics, which deals with the nature of reality–of what exists. The traditional goal of ontological inquiry, in particular, is to divide the world “at its joints,” to discover those fundamental categories or kinds that define the objects of the world. So viewed, natural science provides an excellent example of ontological inquiry. For example, a goal of subatomic physics is to develop a taxonomy of the most basic kinds of objects that exist within the physical world (e.g., protons, electrons, muons). Similarly, the biological sciences seek to categorize and describe the various kinds of living organisms that populate the planet.
The natural and abstract worlds of pure science, however, do not exhaust the applicable domains of ontology. There are vast, human-designed and human-engineered systems such as manufacturing plants, businesses, military bases, and universities in which ontological inquiry is just as relevant and just as important. In these human-created systems, ontological inquiry is primarily motivated by the need to understand, design, engineer, and manage such systems effectively. Consequently, it is useful to adapt the traditional techniques of ontological inquiry in the natural sciences to these domains as well.
The IDEF5 method provides a theoretically and empirically well-grounded method specifically designed to assist in creating, modifying, and maintaining ontologies. Standardized procedures, the ability to represent ontology information in an intuitive and natural form, and higher quality results enabled through IDEF5 application also serve to reduce the cost of these activities.
Basic Principles of Ontological Analysis
Ontological analysis is accomplished by examining the vocabulary that is used to discuss the characteristic objects and processes that compose the domain, developing rigorous definitions of the basic terms in that vocabulary, and characterizing the logical connections among those terms. The product of this analysis, an ontology, is a domain vocabulary complete with a set of precise definitions, or axioms, that constrain the meanings of the terms sufficiently to enable consistent interpretation of the data that use that vocabulary.
An ontology includes a catalog of terms used in a domain, the rules governing how those terms can be combined to make valid statements about situations in that domain, and the sanctioned inferences that can be made when such statements are used in that domain. In every domain, there are phenomena that the humans in that domain discriminate as (conceptual or physical) objects, associations, and situations. Through various language mechanisms, we associate definite descriptors (e.g., names, noun phrases, etc.) to those phenomena. In the context of ontology, a relation is a definite descriptor referring to an association in the real world; a term is a definite descriptor that refers to an object or situation-like thing in the real world.
In constructing an ontology, we try to catalog the descriptors (like a data dictionary) and create a model of the domain, if described with those descriptors. Thus, in building an ontology, you must perform three tasks: 1) catalog the terms; 2) capture the constraints that govern how those terms can be used to make descriptive statements about the domain; and 3) build a model that, when provided with a specific descriptive statement, can generate the “appropriate” additional descriptive statements. The expression appropriate descriptive statements means two things. First, because there are generally a large number of possible statements that could be generated, the model generates only the subset that is “useful” in the context. Second, the descriptive statements that are generated represent facts or beliefs typically held by an intelligent agent in the domain who had received the same information. The model is then said to embody the sanctioned inferences in the domain. It is also said to “characterize” the behavior of objects and associations in the domain. Thus, an ontology is similar to a data-dictionary but includes both a grammar and a model of the behavior of the domain.
IDEF5 Concepts
The IDEF5 ontology development process consists of the following five activities.
- Organizing and Scoping. The organizing and scoping activity establishes the purpose, viewpoint, and context for the ontology development project, and assigns roles to the team members.
- Data Collection. During data collection, raw data needed for ontology development is acquired.
- Data Analysis. Data analysis involves analyzing the data to facilitate ontology extraction.
- Initial Ontology Development. The initial ontology development activity develops a preliminary ontology from the data gathered.
- Ontology Refinement and Validation. The ontology is refined and validated the ontology to complete the development process.
IDEF5 Ontology Languages
Supporting the ontology development process are IDEF5’s ontology languages. There are two such languages: the IDEF5 schematic language and the IDEF5 elaboration language. The schematic language is a graphical language, specifically tailored to enable domain experts to express the most common forms of ontological information (see Figure 1). This enables average users both to input the basic information needed for a first-cut ontology and to augment or revise existing ontologies with new information. The other language is the IDEF5 elaboration language, a structured textual language that allows detailed characterization of the elements in the ontology.
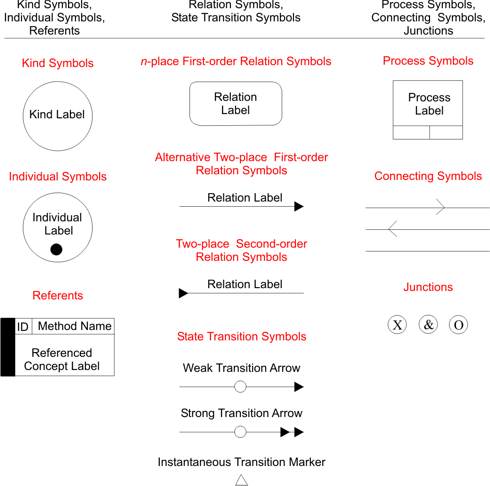 Figure 1: Basic IDEF5 Schematic Language Symbols
Figure 1: Basic IDEF5 Schematic Language Symbols
Various diagram types, or schematics, can be constructed in the IDEF5 Schematic Language. The purpose of these schematics, like that of any representation, is to represent information visually. Thus, semantic rules must be provided for interpreting every possible schematic. These rules are provided by outlining the rules for interpreting the most basic constructs of the language, then applying them recursively to more complex constructs.
However, the character of the semantics for the Schematic Language differs from the character of the semantics for other graphical languages. Specifically, each basic schematic is provided only with a default semantics that can be overridden in the Elaboration Language. The reason for this is that the chief purpose of the Schematic Language is to serve as an aid for the construction of ontologies; they are not the primary representational medium for storing them. That task falls to the Elaboration Language. The Schematic Language is, however, useful for constructing first-cut ontologies in which the central concern is to record, in a rough way, the basic elements that exist in a domain, their characteristic properties, and the salient relations that can be obtained among objects of those kinds and among the kinds themselves. Consequently, the basic constructs of the Schematic Language are designed specifically to capture this type of information.
IDEF5 Schemantic Types
Certain relations predominate when people express their knowledge about a domain; because of their prominence and importance, these relations are included explicitly in the IDEF5 language. There are four primary schematic types derived from the basic IDEF5 Schematic Language which can be used to capture ontology information directly in a form that is intuitive to the domain expert.
Classification Schematics
Classification schematics provide mechanisms for humans to organize knowledge into logical taxonomies. Of particular merit are two types of classification: description subsumption and natural kind classification. In description subsumption, the defining properties of the “top-level” kind K in the classification, as well as those of all its subkinds, constitute rigorous necessary and sufficient conditions for membership in those kinds. Additionally, the defining properties of all the subkinds are “subsumed” by the defining properties of K in the sense that the defining properties of each kind entail the defining properties of K; the defining properties of K constitute a more general concept. Conversely, natural kind classification does not assume there are rigorously identifiable necessary and sufficient conditions for membership in the top-level kind K. Nonetheless, there are some underlying structural properties of its instances that, when specialized in various ways, yield the subkinds of K. The difference between the two types of classification is illustrated in the example below.
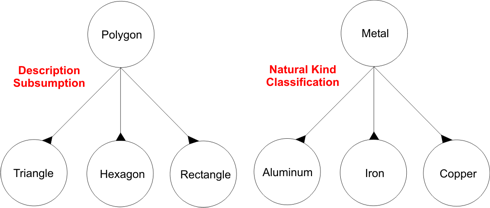 Figure 2: Different Types of Classification
Figure 2: Different Types of Classification
Composition Schematics
Composition schematics serve as mechanisms to represent graphically the “part-of” relation that is so common among components of an ontology. In particular, this capability enables users to express facts about the composition of a given kind of object. For example, one might want to represent the component structure for a certain kind of ballpoint pen.
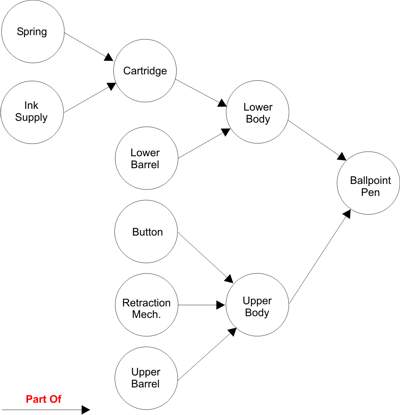 Figure 3: Composition Schematic for the Kind Ballpoint Pen
Figure 3: Composition Schematic for the Kind Ballpoint Pen
As the schematic in the figure shows, the ballpoint pen in the domain in question has both an upper body and a lower body, and that the former consists of a button, a retraction mechanism, and an upper barrel while the latter consists of a lower barrel and a cartridge, which in turn consists of a spring and an ink supply.
Relation Schematics
Relation schematics allow ontology developers to visualize and understand relations among kinds in a domain, and can also be used to capture and display relations between first-order relations. The motivation for developing this capability is that people often describe and discover new concepts in terms of existing concepts. This means of creating and defining new concepts is consistent with Ausubel’s theory of learning, wherein learning often occurs by subsuming new information under more general, more inclusive concepts (Novak & Gowin, 1984; Sarris, 1992). Based on this hypothesis, a natural way to describe a new (or poorly understood) relation is to connect it to a relation that is already well understood and, more generally, to categorize its place in a “conceptual space” of other relations. The IDEF5 relation library (included as an appendix in the IDEF5 Ontology Capture Method Report) provides a baseline reference to help users discover and characterize relations.
Object State Schematics
Because there is no clean division between information about kinds and states and information about processes, the IDEF5 schematic language enables modelers to express fairly detailed object-centered process information (i.e., information about kinds of objects and the various states they can be in relative to certain processes). Diagrams built from these constructs are known as Object-State Schematics.
Two types of changes can be observed in the objects undergoing processes: change in kind and change in state. There is no formal difference between these two types of change: objects of a given kind K that are in a certain state can simply be regarded as constituting a subkind of K. For formal purposes, for example, warm water can be regarded as a subkind of water. However, it is useful to distinguish the two in the schematic language to indicate explicitly the kind of thing that is in a certain state. This is done using colon notation (e.g., kind:state). For example, warm water will be indicated by the label water:warm, frozen water by water:frozen, and so on. The IDEF5 schematic language allows modelers to visually represent changes in an object’s kind or state as well as the processes that bring about such changes.
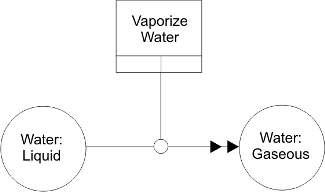 Figure 4: Example Object State Transition Schematic
Figure 4: Example Object State Transition Schematic
Summary
The nature of any domain is revealed through three elements: 1) the vocabulary used to discuss the characteristic objects and processes comprised in the domain, 2) rigorous definitions of the basic terms in that vocabulary, and 3) characterization of the logical connections between those terms. An ontology is a domain vocabulary complete with a set of precise definitions, or axioms, that constrain the meanings of the terms in that vocabulary sufficiently to enable consistent interpretation of data. The IDEF5 method provides a structured technique, by which a domain expert can effectively develop and maintain usable, accurate domain ontologies. The IDEF5 method is used to construct ontologies by capturing assertions about real-world objects, their properties, and their interrelationships.
References
Novak, J., and Gowin, D. B. (1984). Learning How to Learn. Cambridge: Cambridge University Press.
Sarris, A. K. (1992). “Needs Analysis and Requirements Document: Integration Toolkit and Methods, Corporate Data Integration Tools.” MANTECH Report WL-TR-92-8027. WPAFB, OH.
It seems to me IDEF0 for your high-level works best and IDEF3 for your more detailed efforts but I am still new to this language.